Examples
Survival Analysis, Cox Regression, Concordance Index, Cross Validation
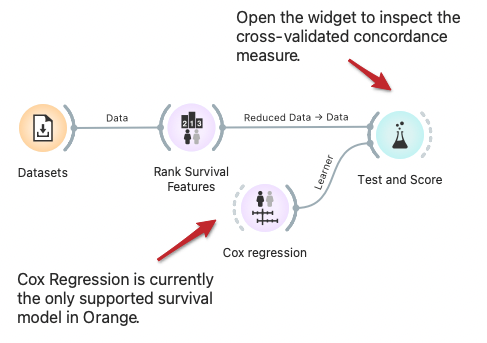
Cross Validation for Survival Models
DownloadOrange built-in methods for testing and scoring the predictive models now support survival-related models like Cox regression. Here we demonstrate cross-validation to estimate the concordance index for the Cox regression model trained on data instances from selected features.
Clustering, Hierarchical Clustering, Box Plot
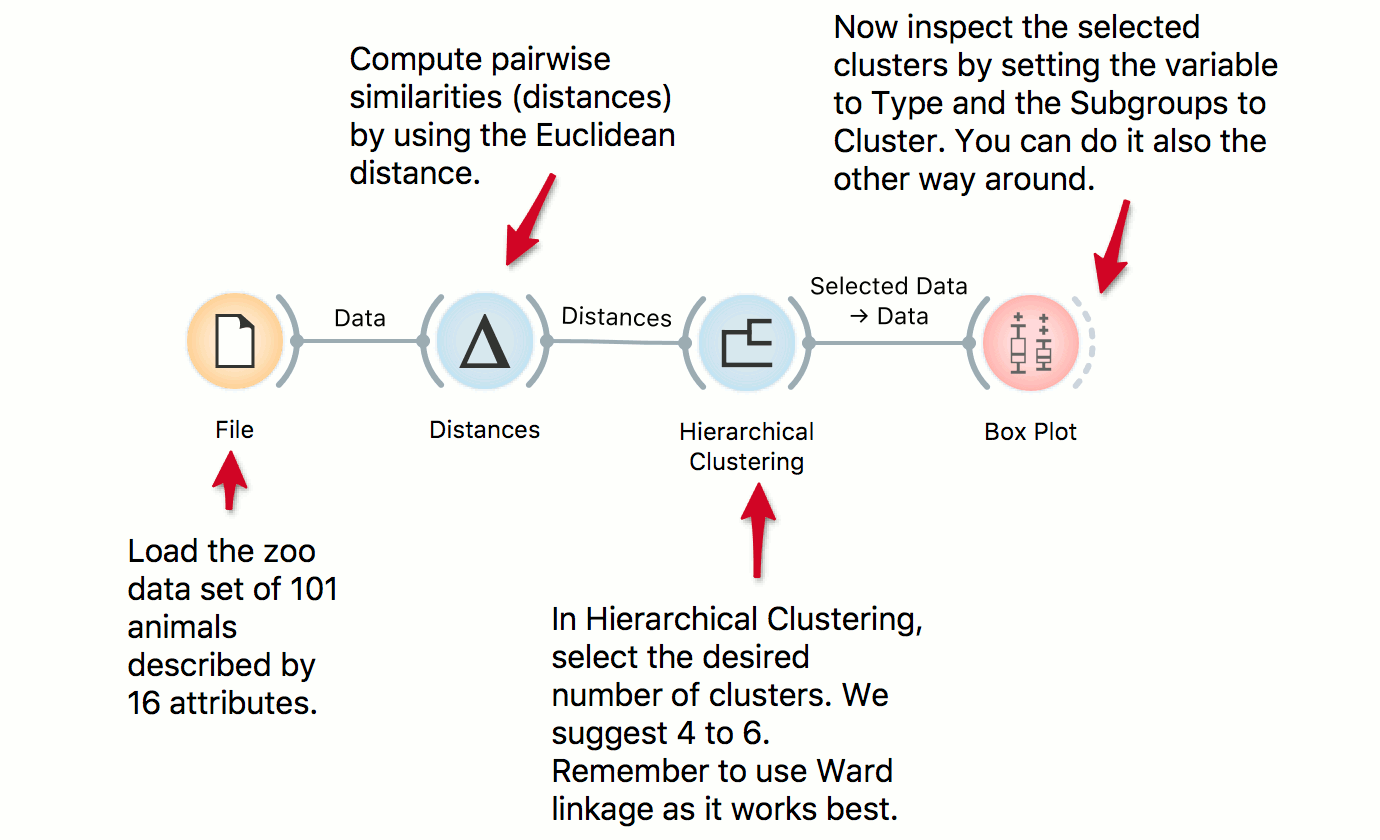
Cluster Inspection
DownloadWe use the zoo data set in combination with Hierarchical Clustering to discover groups of animals. Now that we have the clusters we want to find out what is significant for each cluster! Pass the clusters to Box Plot and use 'Order by relevance' to discover what defines a cluster. Seems like they are well-separated by the type, even though the clustering was unaware of the class label!
Survival Analysis, Kaplan-Meier, Cox Regression
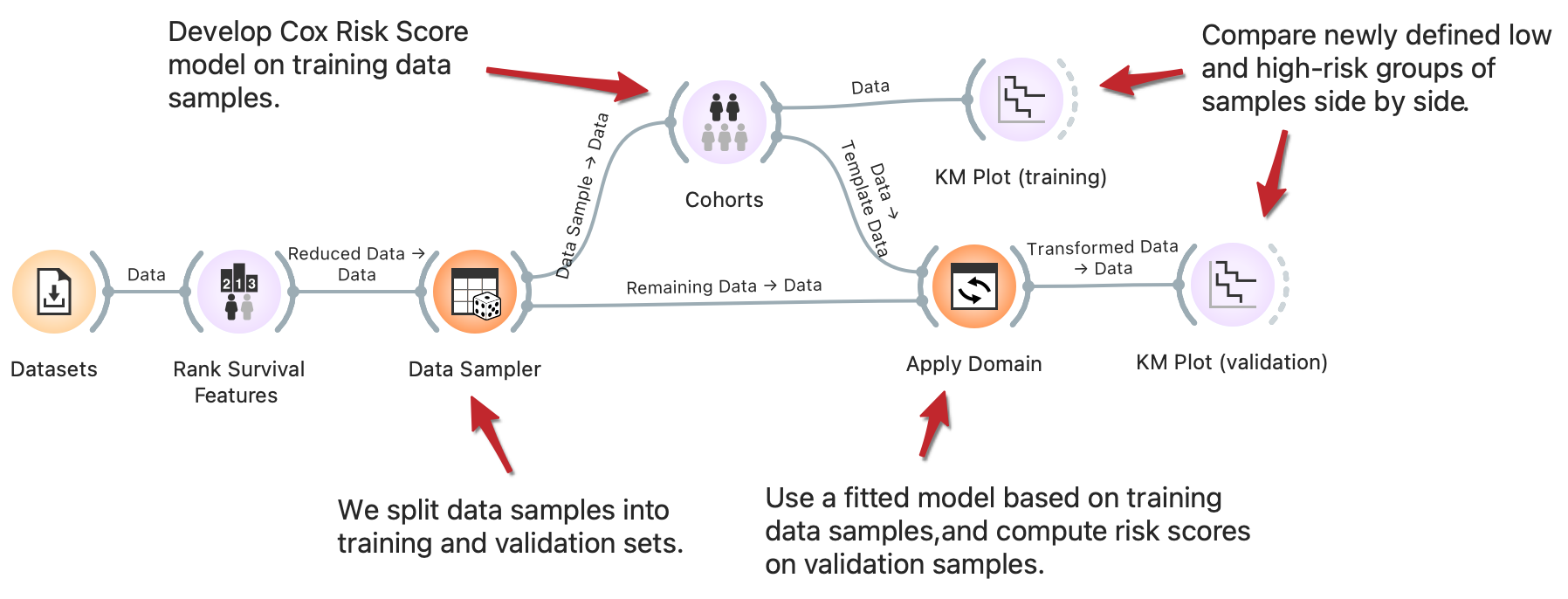
Cohort Construction and Validation
DownloadStratification of patients into low and high-risk groups is a common task in survival analysis to identify clinical and biological factors that contribute to survival. One approach to stratification is by computing risk score values based on the Cox regression model. With the clever use of Orange widgets, we can split the data into training and validation sets and then interactively generate risk score models on training data to observe the difference in cohorts' survival rate on training and validation samples side-by-side. Read more on how Apply domain enables this kind of workflows.
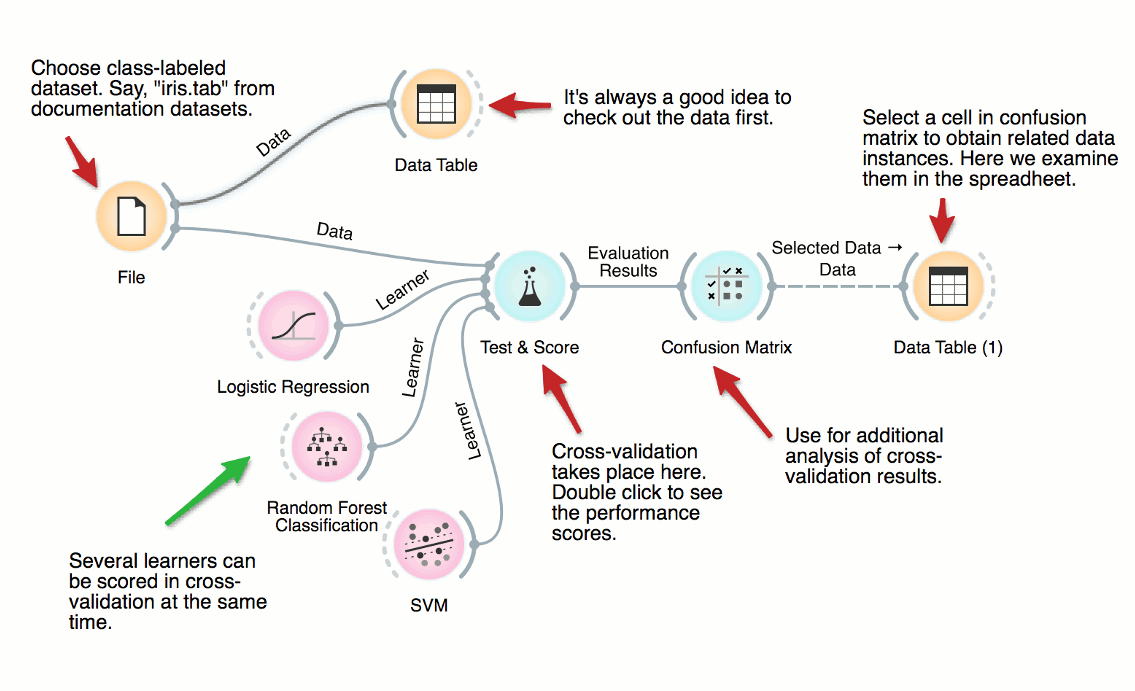
Cross Validation, Predictive models, Classification
Cross Validation
DownloadHow good are supervised data mining methods on your classification dataset? Here's a workflow that scores various classification techniques on a dataset from medicine. The central widget here is the one for testing and scoring, which is given the data and a set of learners, does cross-validation and scores predictive accuracy, and outputs the scores for further examination.
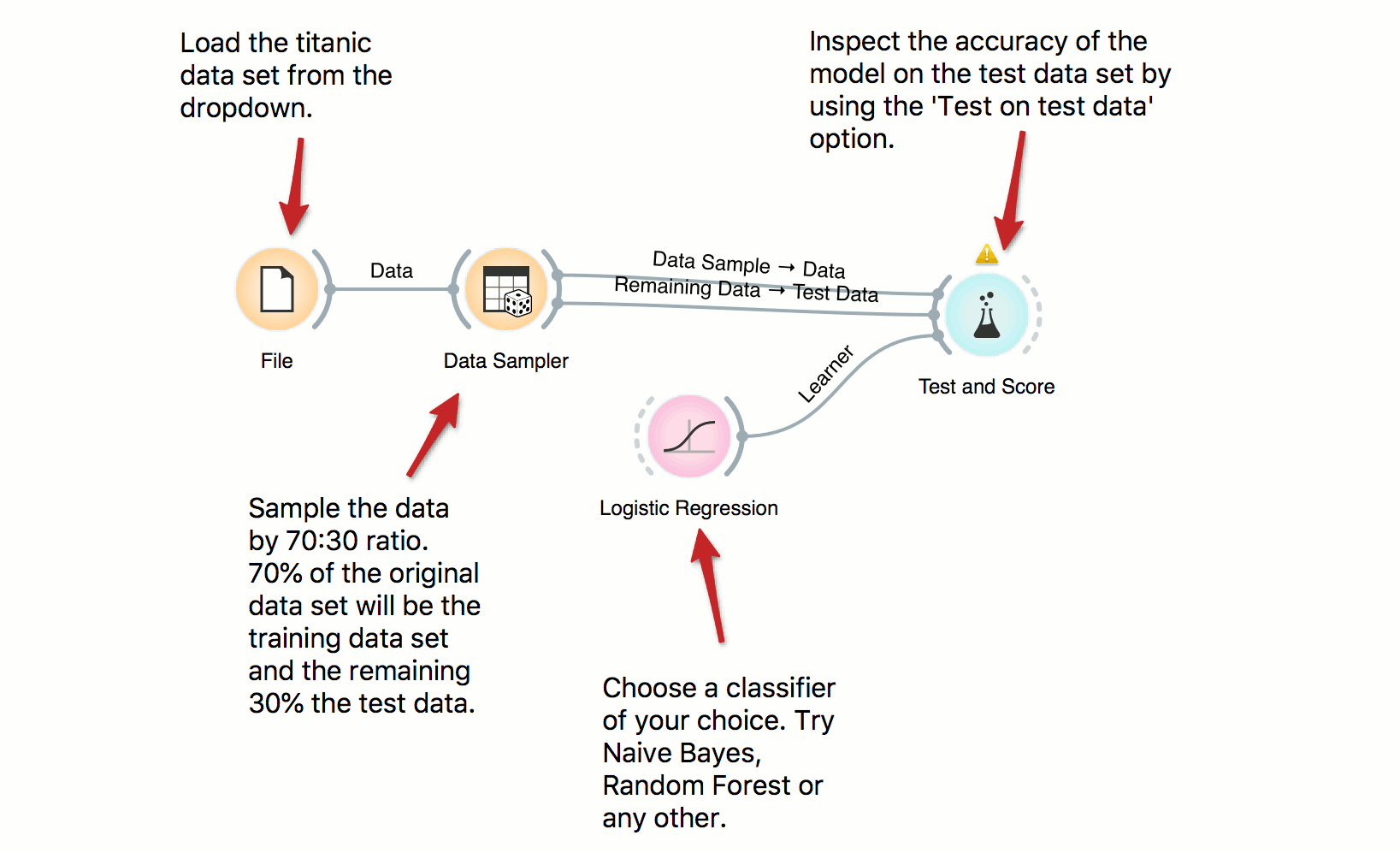
Classification, Data Sampler, Predictive models
Train and Test Data
DownloadIn building predictive models it is important to have a separate train and test data sets in order to avoid overfitting and to properly score the models. Here we use Data Sampler to split the data into training and test data, use training data for building a model and, finally, test on test data. Try several other classifiers to see how the scores change.